
IBM Connections and your Core Group Coordinator
Issue:
Despite both servers of a cluster being up in the WebSphere ISC, the cluster itself in the Cluster overview (WebSphere application server clusters) would show a light red cross, which usually indicates that at least one server is down. Also the whole Connections environment is very unstable with applications like files and wikis suddenly not willing to load for part of the population. SystemOut.logs show a large number of these errors:
AgentClassImp W HMGR1001W: An attempt to receive a message of type GrowAgentRequest for Agent Agent: : [_ham.serverid:ConnectionsCell01\ConnectionsNode11\SearchServer01] [drs_inst_name:ic/services/cache/OAuth20DBClientCache][drs_inst_id: 1512698926654][ibm_agent.seq:1227][drs_mode:0][drs_agent_id: CommunitiesServer01\ic/services/cache/OAuth20DBClientCache\926654\1] in AgentClass AgentClass : [policy:DefaultNOOPPolicy][drs_grp_id: ConnectionsReplicationDomain] failed. The exception is com.ibm.wsspi. hamanager.HAGroupMemberAlreadyExistsException: The member already exists
Explanation:
In larger environments it’s common to cluster your IBM Connections applications. The WebSphere High Availability Manager (HAM) is the component that responsible for the automatic failover support. The location of the services that depend on the HAM is managed by the core group coordinator. The recommended value for the amount of servers that are managed by the core group coordinator is 50. Up to a 100 is possible, but then you may need to provide more resources to your coordinator. By default, HAManager selects the lexicographically lowest named server from the available core group members for the core group coordinator. The lexicographic sort uses “Cell Name/Node Name/Server Name”. In practice however, the core group coordinator starts on the first jvm that starts in a cell and that’s usually the deployment manager. It would only move to another node if the deployment manager is stopped. In our case ‘ConnectionsManager’ is lexicographically also lower then ‘ConnectionsNode’, so if the core group coordinator would be on another node, it would end up back at the deployment manager if that node was restarted.
In the environments I’ve worked in, the number of servers per application ranged from 2 to 4. If you choose for a Large deployment during installation, the total number of servers becomes large pretty fast. With 4 servers per application, it actually easily exceeds a 100. According to the WebSphere people you should have 2 coordinators is that case. However, for IBM Connections only one coordinator is supported (this information is for Connections 5.5. I don’t know if IBM changed their support statement regarding the number of coordinators for IBM Connections 6). This limit of a 100 is not fictitious. We did get error messages when we exceeded it. For that reason we had to bundle applications on one JVM.
The issue described above however occurred in the environment with 2 servers per application. This amounted to about 65 JVMs. Though that number isn’t that far from the recommended amount of servers per core group coordinator, the problems were severe. The reason for these problems turned out to be an architectural decision that was made by my predecessor in this environment. The Deployment manager had to share it’s resources with both Cognos and a JVM running Kudos Analytics. Kudos Analytics was assigned a min/max heap size of 6GB. Cognos was assigned a min/max heap size of 2/6 GB. The deployment manager had 1GB assigned to it and the node agent 384MB. Total memory in this (windows) server: 14GB (yes, 14. Don’t ask). You can do the math. Also, Cognos is very cpu hungry, so just adding more memory would not necessarily do the trick.
Solution:
To stabilize the environment we had to take actions to provide enough resources to the core group coordinator. As there was no quick way to free up resources on the deployment manager, we had to find other WebSphere servers in the cell that weren’t heavily loaded. We chose the node agents of our IBM Docs File viewer/conversion servers for that. We upped the memory of the node agents, and set them as the preferred nodes for the core group coordinator. You can do this in the WebSphere ISC under Servers -> Core groups -> Core group settings -> DefaultCoreGroup -> Preferred coordinator servers.
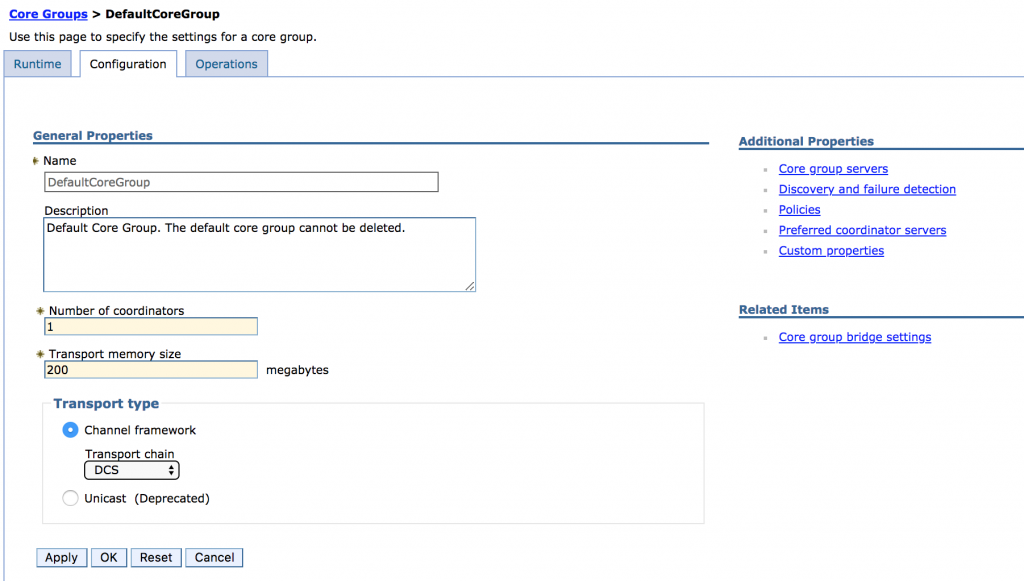
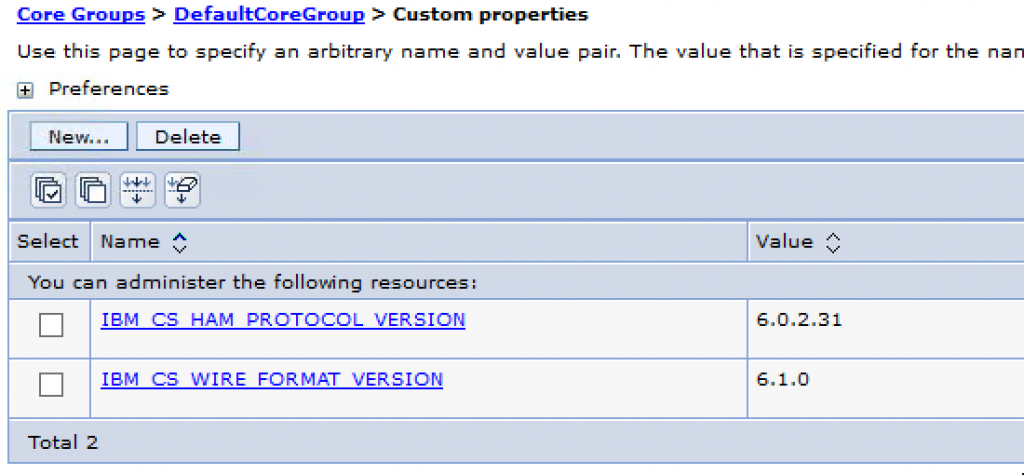
Next to that, by suggestion of IBM, we increased the memory for the core group coordinator to 200MB (from the 100MB default) and set 2 custom properties for the DefaultCoreGroup:
- IBM_CS_HAM_PROTOCOL_VERSION – 6.0.2.31
- IBM_CS_WIRE_FORMAT_VERSION – 6.1.0
These actions improved stability by a large degree and the HMGR1001W errors were gone. As a long term solution I managed to get an extra server and moved both Cognos and Kudos Analytics away from the deployment manager, leaving just the deployment manager and a node with a JVM for DomainPatrol Social on it. After that I set the Deployment Manager back as the preferred node for the core group coordinator.
Lessons learned:
The biggest lesson learned here for me was definitely: Don’t underestimate the importance of your deployment manager. You might think it’s not doing that much, but it does more than you might think and starving it for resources is simply a very bad idea. Combining it with Cognos as I’ve seen suggested in some manuals, might not be the smartest idea. I’ve also seen it combined with TDI. I guess as TDI is usually only used at nighttime and, if used single threaded, only uses one cpu anyway, that might be a better candidate if you want to save on your number of servers.
Resources:
These were the suggested resources by IBM in the PMR that resulted from this issue:
https://www.ibm.com/support/knowledgecenter/en/SSAW57_8.0.0/com.ibm.websphere.nd.doc/info/ae/ae/trun_ha_cfg_replication.html
