
Customising your TDI assemblyline – Part I
At the last Social Connections/LetsConnect conference in September of this year in München, I had the honour to present a session about customising your TDI assemblyline. During that session I promised to write a blog post about the customisations I made to the assemblyline of one of my customers. The idea behind it is that others who have played around with customising their TDI assemblyline would comment on it and together we would write the much needed documentation on how to make customisations. It would be great if this article becomes a community effort. Lack of documentation on how to make customisations is a severe problem we all face when we start. Just to be clear, I’m not talking here about customisations that can be done through the map_dbrepos_from_source.properties, map_dbrepos_to_source.properties, profiles_functions.js and profiles_tdi.properties files. Obviously you should always look first if you can fill the profiles database through the standard assemblyline and being smart about using the aforementioned files. However, when you need to include a 2nd directory or need to create “default values”, you’re usually stuck with making your own customisations.
When you need to customise the assemblyline you basically have two choices:
- Customise the IBM/HCL provided default assemblyline
- Create a 2nd assemblyline with all customisations which is run after the default assemblyline
As became apparent during my session, within the community opinions differ on when to choose what. Some people feel that the default assemblyline should only be used for the bare basics and anything special should be put in a separate assemblyline. My view is that as long as changes to the default assemblyline are small and easily reproduceable, changing the default assemblyline is better as running one assemblyline is simply more efficient than running two and, if you know where to insert your customisations, it’s also faster as you can work with what’s already there. However, if your customisations include writing to other systems or other customisations which can’t be considered “small”, by all means use a 2nd assemblyline! In the title of this blog I suggest that there will be a part II. My idea is that part one will show how to make customisations to the default assemblyline, while part II will be about creating a separate assemblyline. If you see anything which can be done in a better way, please let me know!
My ‘small’ changes
To give you an idea of what I consider small, I’ll give an overview of the changes I needed to make to the default assemblyline:
- My main directory was a Novell e-directory which was filled with information which came from the HR department. For the uid I however needed the Windows logonname from the Active directory as the client would use spnego for single sign-on. This information was not in the e-directory. I therefore needed connections to two separate directories
- The Display name in the Active Directory was better than the one in the e-directory. I therefore needed to grab the display name from the AD
- The email address was taken from the e-directory. Unless it wouldn’t exist there, then it should be grabbed from the AD
- The AD would be the only authentication directory. Users who appeared in the e-directory, but not in the AD should therefore not get a Connections profile as they wouldn’t be able to login anyway
- The employee location information in the HR systems would not always be up to date. We therefore wanted to enter this information as an initial value, but users should be able to edit this value themselves afterwards
- Same was true for the job title
- Managers were listed in the e-directory by their corporate key. For the Mark_Managers script to work, these needed to be listed by their uid
Some terminology
When you dive into a subject like this, you can’t avoid talking about some terminology. Here are some terms which are important in the context of Tivoli Directory Integrator. They come from the TDI user manual.
- Connector
Connectors are the components that connects the assemblyline to sources and targets. There are many connectors and it’s unlikely that you need to connect TDI to a source for which a connector doesn’t exist yet. Connectors can Add, Delete, Update or Lookup entries or iterate a directory or create a delta - Entry
All the Attributes that make up a single unit of data- Work entry
This is where all the info for the currently processed person is kept - Conn(ector) entry
The info that comes back from the current connector. You usually use this entry to update the work entry - Other entries (current, error, operation)
There are other types of entries which you might need in advanced situations. I didn’t need these for my work
- Work entry
- Attribute map
Data flows between conn entries and work entries. There’s an Input map and an Output map - Iterator
This is the process that iterates over all entries it finds in a Connector (in our case either the SQL database or the LDAP directory)
Where to insert the code
My biggest problem when making the customisations was: Where do I start? To know where the insert the code we have to know how the assemblyline is built in a functional way. IBM described this as the 5 phases of the sync_all_dns process:
- Hash Profiles database
TDI makes a connection to the SQL backend to make a hash of all records - Hash source (LDAP)
Next TDI iterates over all LDAP entries and creates a hash of these values - Compare values
The values from steps 1 and 2 get compared and based on this comparison a couple files are created:- employee.adds
all the users which were found in the source and aren’t in the profiles database yet - employee.updates
all the users where the hashes from the profiles database and source differ - employee.delete
All users who were in the profiles database, but were not found in the LDAP source - employee.skip
All users that were skipped in the code - employee.error
All user entries where TDI ran into an error when trying to update/create them
- employee.adds
- Delete
All the users who are in employee.delete get deleted - Add / update
All the entries of the users who are in the employee.add and employee.update files are added/updated in the profiles database
What we basically want to do is create a work entry with the combined information from all sources before that information gets hashed and compared. We therefore need to insert our code in phase 2. In this phase, TDI iterates over all entries it finds in the source LDAP and creates a work entry. If we add a 2nd connector in this step, we can use the conn entry from this 2nd connector to update the work entry.
Editting the assemblyline
To start the TDI editor, you need to run the ibmditk binary. I prefer to create a batch file or shell script in the program directory to start the TDI editor with the right working directory. Such a script would look like this:
/opt/IBM/TDI/V7.1.1/ibmditk -s /opt/IBM/TDISOL
The first time you start the editor, your navigator will be empty. You want to go to File -> Open Tivoli Directory Integrator Configuration File and select profiles_tdi.xml from your TDI Solution directory. Give your assemblyline a name (the name doesn’t matter) and you will see a navigation tree. In this tree you can find “sync_all_dns_iterate” which is the entry that we want to change.
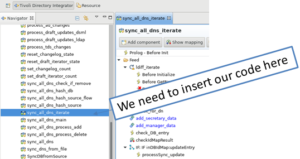
First however we need to define new Connectors. I needed a connector to our extra LDAP directory as well as a lookup connector to the SQL database. These connector were necessary to:
- Collect 3 attributes from the Active Directory for the current user in the work entry
- Lookup the LoginId of the Manager in the Active directory
- Lookup the current value in the SQL database for specific attributes (the initial values)
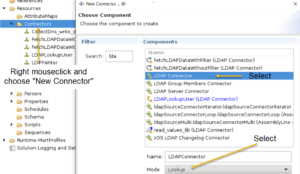
Creating the Connectors
To create a connector, expand the Resources in the navigation pane and right click on the Connectors. You can now select to create a new Connector. When you want to create a connector to an active directory or another LDAP directory, choose an LDAP Connector. As we just want to lookup users in this 2nd directory to add information to our work entry, we choose “lookup” as Mode. Also don’t forget to give your connector a nice descriptive name. I named mine “AD_LookupUser”. Notice that you can also choose the existing LDAPLookupUser connector as a base for a new connector. As we want to create a connector to a 2nd directory, this doesn’t make sense now.
After you press ‘Next’ you can configure the connector. You can either configure the connector here or configure it when you use it in the assemblyline. I feel it’s good practice to configure the general components (the components you’re currently seeing) of the connector here and only configure specifics (like which fields to collect exactly) in the assemblyline. I hope I don’t have to explain that it’s not good practice to put the information like the url and username/password straight in the xml of the assemblyline. You want to put this type of information in property files. Therefore select the icon to the right of each field. You can now select to either use a property from an existing property file (like profiles_tdi.properties), add a property to an existing property file or select a new property file. There are good arguments for putting them in profiles_tdi.properties which contains all other properties for the assemblyline as well as creating a separate property file for all your customisations. I chose to create a separate property file in the end, but feel free to use profiles_tdi.properties. You would usually configure your ldap server as ldaps://<yourhost>:636 which includes both the ssl flag as well as the port which otherwise wouldn’t be configurable through a property.
After you press Finish you have created your first connector. I needed a 2nd connector as I needed to lookup values in the SQL database. The principle is the same. Create a new connector (in this case a Database Connector (JDBC) ), give it a desciptive name and configure the JDBC URL, JDBC driver, the username and password (if the same for all databases, otherwise it might be better to do this on use of the connector).
**************** note ****************
After my presentation at Social Connections I was asked why I didn’t use the Profile Connector. The reason is simple: I wasn’t aware of the Profile Connector. I’ve since looked at it. The Profile Connector is the only connector you may use to make edits in the profile database. When you only do a lookup, using a jdbc connector is fine. I’ve tried to recreate my script using the Profile Connector, but so far I have been unable to read the extension attributes through the Profile Connector (even though it looks like it should be simple, I simply can’t get the value from the extension attributes). If someone knows how to do this, please let me know in the comments!
************************************
Adding components to the assemblyline
It’s time to use our new connectors in the assemblyline. Expand the AssemblyLines category and double-click on sync_all_dns_iterate to open it in the Assemblyline Editor. The Data Flow will show which steps are taken to for each record the iterator iterates over. We want to add our components to this, so click on Add component and choose our first connector (in my case the AD_LookupUser connector). Give it a nice descriptive name and press Next or Finish (if you entered all information for the active directory already in the connector, the just press finish).
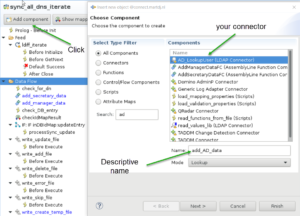
You will find your new Component back at the bottom of the Data Flow. You can simply drag & drop it to the right place to process it in the right order.
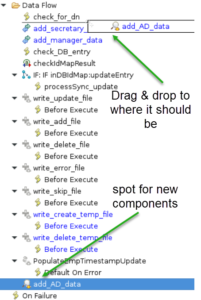
Now it’s time to configure your new component and at this point it comes in handy when you can program in JavaScript.
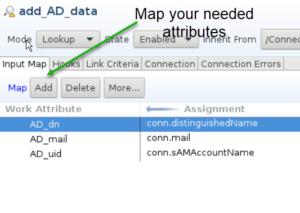
In the Input Map, add all the attributes which you need from the 2nd directory and assign them a name in the Work entry. Afterwards you can either use them later in the data flow or assigned them to a field in the User profile through the map_dbrepos_from_source.properties file. The hooks are where you start programming. I configured the On Multiple Entries, On No Match, Lookup Error and Default on Error hooks.
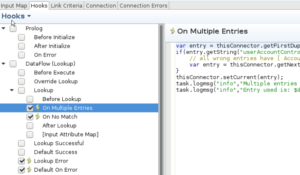
My code for On Multiple Entries was:
var entry = thisConnector.getFirstDuplicateEntry();
if(entry.getString("userAccountControl") != '512') {
// all wrong entries have [ AccountDisabled, NormalAccount ] in that field which gives a code of 514. NormalAccounts have a code 512
var entry = thisConnector.getNextDuplicateEntry();
}
thisConnector.setCurrent(entry);
task.logmsg("info","Multiple entries (" + thisConnector.getDuplicateEntryCount() + ") found for user " + entry.getString("CN"));
task.logmsg("info","Entry used is: $dn " + entry.getString("$dn") + " and sAMAccountName " + entry.getString("sAMAccountName"));
As you can see, this is JavaScript. I found that some people had multiple entries in the Active directory, so I had to cover this case in the connector. These people would at a maximum have one active account which could be recognised by the fact that the userAccountControl would have a value of 512. Notice that in the conn(ector) entry all attributes of the LDAP record are available. I cycle through the LDAP records till I find an active record. I strongly recommend the use of task.logmsg in all parts of your custom code to create proper logging for the assemblyline. My life when troubleshooting entries that went wrong became a lot easier because I had relevant log messages in the ibmdi.log file.
If there was no AD record for a user or the connector encountered some sort of error, I would skip the entry, which means that no record will be created for this user in the Profiles database. I wrote this code for that:
task.logmsg("info","*** Processing " + work.uid + " , " + work.mail + " ***");
task.logmsg("info","No AD record found for user " + work.uid + ", " + work.mail + ". User skipped")
system.skipEntry()
system.skipEntry() is obviously the relevant function. Also notice that you can grab information from your current work entry to enrich your log.
Next are the Link Criteria. Which unique attributes do your primary LDAP directory and 2nd LDAP directory have in common? In my case the ‘uid’ of the first directory was the same as the ‘cn’ in my active directory. The $-sign is needed to make clear to TDI that we mean the value of the variable uid in the work entry and not the word ‘uid’.
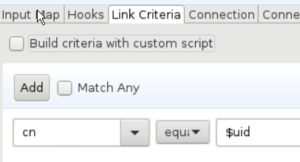
The connection field was already filled in the Connector component itself, so no reason to change it here. Notice though that you can change it here.
So the first component is added. For me it was time now for some script in the data flow to get the email properly assigned. To do this I added another component. This time an Empty Script component.
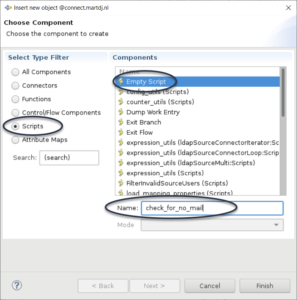
I dragged and dropped this script component to straight under my previous connector component. I then put this script in the component:
function isEmpty(value){
return (value == null || value.length === 0 || value.trim().length === 0);
}
if(isEmpty(work.getString("mail"))){
if(isEmpty(work.getString("AD_mail"))) {
task.logmsg("info","No mail address was found for user " + work.uid + ". Entry skipped");
system.skipEntry()
} else {
work.mail=work.AD_mail;
}
}
What this script does is, it checks if the mail attribute of the work entry is empty. If it is, it fills it with the mail attribute of the active directory unless that attribute is also empty, in which case the whole entry is skipped. Reason for the latter is that a person without an email address is usually not a real person (but some robot account etc). Just note that if your company uses Exchange mail, the AD would be the prime source of information for the email address, so it would make sense to turn this code around. Also note that instead of adding the script component, I could also have done the same in the Lookup Successful trigger of the add_AD_data component. Multiple ways lead to Rome.
Next step was the create the “initial values” in the profiles database. The idea was that only if a value existed in the source directory and not in the profiles database, it should be updated in the profiles database. If a value already existed in the profiles database, that value should remain as to allow the user to update the initial value without it being overwritten afterwards. In TDI terms, the work entry will contain the values from the LDAP directory, but if values exist in the SQL database for these fields, the values in the work entry should be replaced by these values from the SQL connector.
From the previous connector, we know the drill now. We add a component to our data flow and select our SQL Connector which we created earlier. We drag and drop it to the place in the data flow where it should be executed (in my case under the ‘check_for_no_mail’ script). Then we enter the values. In the input map I assigned all values that I needed in my code later on.
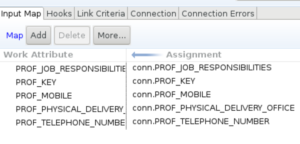
Next I configured the hooks. The main hook was the “Lookup Successful” hook. My script for this hook was:
function isEmpty(value){
return (value == null || value.length === 0 || value.trim().length === 0);
}
if(conn != null){
if(!isEmpty(conn.getString("PROF_MOBILE"))){
work.TDI_mobileNumber=conn.getString("PROF_MOBILE");
}
if(!isEmpty(conn.getString("PROF_JOB_RESPONSIBILITIES"))){
work.TDI_jobTitle=conn.getString("PROF_JOB_RESPONSIBILITIES");
}
if(!isEmpty(conn.getString("PROF_PHYSICAL_DELIVERY_OFFICE"))){
work.TDI_physicaldeliveryofficename=conn.getString("PROF_PHYSICAL_DELIVERY_OFFICE");
}
if(!isEmpty(conn.getString("PROF_TELEPHONE_NUMBER"))){
work.TDI_telephonenumber=conn.getString("PROF_TELEPHONE_NUMBER");
}
work.setAttribute("isNewUser", "false");
}
I start with defining a function which defines when I consider a value to be empty. Then I check for each attribute whether it has a value. If so, replace the current value in the work entry. The last script line is necessary for my next component where I do the same, but for a value in the profile_extensions. I’ve added a new connector for that which connects to the PROFILE_EXTENSIONS table.
If the record couldn’t be found I logged this using the task.logmsg function. All my extra log statements give me a log where I can very easily see which records went wrong, which records were new etc. Troubleshooting your assemblyline for specific records is a lot easier with proper logging.
As the rest of my customisations are more of the same, I’m not going to write those out. The only customisations I still want to show are at the top of the sync_all_dns_iterate in the ldiff_iterate component. This is the component where the attributes of your 1st LDAP directory are assigned to your work entry according to you map_db_repos_from_source file. You can also enter script here. 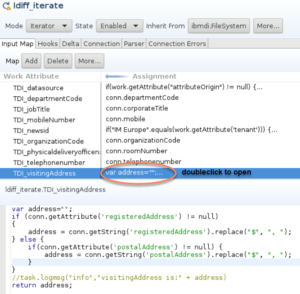
The source directory in this case contained 2 attributes that both could contain an address. The most likely candidate for the visiting address was the registeredAddress, but for many people this address wasn’t filled, yet they had their office location in the postalAddress. This script therefore first checks if there’s a registeredAddress. If there is, it uses this address. Otherwise it uses the postalAddress.
Resources
Once you get into Tivoli Directory Integrator it’s a really powerful tool, but I found the learning curve quite steep. Some resources that helped me on my quest were:
- Tivoli Directory Integrator 7.1.1: Getting Started Guide
- Tivoli Directory Integrator 7.1.1: Users Guide
- Tivoli Directory Integrator 7.1.1: Reference Guide
- IBM Tivoli Directory Integrator Users Group
- Using the Profile Connector (still on the IBM site. I haven’t found this info yet on the HCL site)
What’s next
At the end of my presentation I got the question why I had chosen to customise the existing assemblyline and not created a 2nd assemblyline with my customisations. As explained in my introduction, I felt that for the type of customisations that I needed to do customising the default assemblyline was the right way to go. You have to be aware though that the default assemblyline is maintained by IBM/HCL and when they’re going to provide an updated version, they’re not going to tell you what they changed. Therefore all your customisations have to be easily repeatable. By keeping them in a single component (sync_all_dns_iterate), I feel they are. However, I’d like to write a second blog article on doing the customisations in a second assemblyline. As that’s something I have never done so far, I can use any help I can get, so if you have written an 2nd assemblyline with your own customisations and would like to share it with me, please do!
